
Why You Should Use Intelligent Reporting and Skip the Templates
When it comes to creating automated content, using a heavily templated approach is very enticing. It allows you to quickly set up new content and make sure that the final narratives very closely follow the outline that you set up. I call this a ‘Mad Libs’ approach, since it follows the same basic structure of the kids game, where the blank words in templates are filled in with specific details. Many companies in the Natural Language Generation space have made use of this approach, often thinly papering over their templates by adding a few basic options or paraphrases.
Having watched this industry for over ten years, I’ve seen how a huge percentage of these projects (and the companies connected to them) have failed. So often, it is because template-based approaches have hidden problems that are not apparent to non-experts at first glance.
Before diving into those hidden problems, let’s first establish the alternative to templates- intelligent narratives. Rather than using templates, these narratives are built by: (1) going through data to figure out what the most interesting stories are, and then (2) allowing the most interesting stories to self-assemble into a well-structured narrative. This has the huge advantage of ensuring that all the most compelling content finds its way into the final narrative. While templates wedge the data into the narrative, intelligent reporting builds the narrative around the data.
Sounds way better, right? But then why do some companies try the templated approach? That’s where template’s ‘hidden’ problems come into play. When comparing a single templated report with an intelligent narrative, the template will often not look that much different. In particular, the templated report will seem to do a good job hitting on the ‘main’ points (what was up, down, etc.).
The real problems happen over time, as people read more versions of the templated content and realize they are all fundamentally the same. This causes readers to (1) worry that they aren’t getting the full story, and (2) get tired of having to read through words just to get to the same pieces of data.
Narratives Are Not Predictable

If you have a big data set, the number of possible interesting stories you could write about that data is nearly endless. Which stories will wind up being the most interesting (the ones you will include in your narrative) cannot possibly be known in advance.
Take a football game, for example. Sure, the final score and the teams’ records are pretty much always going to be relevant, but beyond that, it’s chaos. You might have a game where there was a huge comeback, so the flow of scoring over the course of time is the key story. In another game, it was a blowout from the start and the key story is about a player’s stellar statistics. Or, the key story could be the revenge factor a team has after having been eliminated from the playoffs by their opponent in the previous year. I could go on, but you get the point- there is no way to write a template for all these possibilities.
Essentially, templates have to be built to talk about the types of things that always occur. One team wins; one team loses; the winning team’s record is now X; the losing team’s record is now Y; etc. However, it’s the things that rarely happen that are actually the most interesting to the reader. This goes for sports, sales figures, stock movements, you name it. Templates are therefore ironically built to show the exact information that is the least compelling to the reader.
There's A Reason We Don't Like 'Robotic' Writing

On top of doubting that they are getting ‘the real story’, readers having to repeatedly slog through the same information in the same arrangement over and over again will soon be begging to just see the data! This is because the words in a templated report are not actually adding any real information compared to the way they are in a flexible, intelligent narrative.
The idea that words are the key to helping people understand information stems from a fundamental misunderstanding of where the power of narratives comes from. There are two main advantages of a narrative when compared to raw numbers: (1) the ability to include or exclude certain information, and (2) the ability to arrange that information into main points, counter-points, and context. Wrapping words around the exact same set of data points in every report will not realize either of these advantages.
Fundamentally, good reporting is about synthesis, not language. In fact, intelligent reports can use very little language (as in infographics) and still convey a great deal of easy-to-digest information. Without intelligent synthesis, you are better off just giving readers the key pieces of data and letting them piece together the stories themselves.
[Quick note: both this problem and the problem of missing key information are most applicable to situations where end users are reading multiple reports. It is possible you could have a use case where people are only going to read the templated report once. In my experience, however, that circumstance is rare due to the amount of work that needs to be done to set up automated reporting. You typically have to merge your data into the automated reporting system, set up the reports (which take a decent amount of time even if you are using a template), and then set up a distribution system. It’s rare for this procedure to pencil out in use cases that don’t involve readers encountering multiple reports, either because they are getting multiple reports over time (e.g. a weekly recap) or seeing reports on different subjects (e.g. reports on different sales team members).]
Starting Over Next Time
Given the large initial investment in data integration, companies are often interested in applying their automated reporting capability to new, related use cases. In this very likely circumstance, you are much better off having built out your content with flexible intelligence rather than templates. Let’s examine why that is by looking at two different scenarios.
In Scenario #1, you’ve invested in building out an intelligent Generative AI system that synthesizes your data and turns it into compelling, insightful reports. In Scenario #2, you took a shortcut and built out a template-based reporting system. The good news is that in both scenarios you will be able to quickly adapt your narrative generation technology to your new use case.
The bad news, if you are in Scenario #2, is that your new reporting will have all the drawbacks that are inherent to a Mad Libs approach, since you will simply be building a brand new template from scratch. If you built an intelligent system, however, you would be able to apply the already-built intelligent components to the new use case. This reshuffling typically takes the same amount of time that it would take to build a template. Essentially, by building intelligence instead of templates, you can quickly expand quality content at the same rate that you can expand cookie-cutter templates.
In Conclusion
Investing in quality content is going to cost more than a templated approach, and the benefits will not be obvious at the beginning. Over time, however, templates provide little to no value, while intelligent reporting will prove its worth. Trust me on this one: leave the Mad Libs to the kids.
Ok, first things first- pivot tables most certainly DO WORK…at some things. This article is not about why pivot tables are useless, but rather about the ways that pivot tables fall short of solving the data analysis needs for many companies and use cases. I also explain the fundamental reasons WHY they fall short. I focus on pivot tables because they are probably the best tools that currently exist for most companies to run data analysis. If pivot tables can’t help you with your data analysis, then it’s probably the case that no software tools can (that you know of 😉).
How Pivot Tables Can Help
Pivot tables are great at quickly surfacing the most important top-line numbers in your data. Let’s use, as an example, a retail company that has a record of every single sale they've made. They could store each sale as a row in a spreadsheet, showing the date of the sale, price, location, and a product class.
If the company had a large number of sales then the spreadsheet would quickly get unwieldy. Summing up the total sales could be helpful, but what if you wanted to dive into a particular aspect of this sales data? A pivot table gives you that ability, allowing you to, for instance, isolate sales for a given month and then break down those sales by location. It might look something like this:
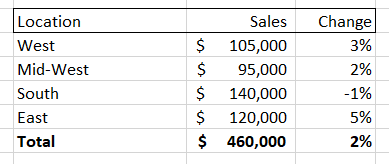
You could also choose to break down the sales numbers by product class, giving you something like this:
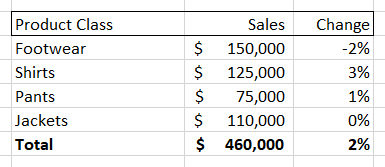
Pivot tables also allow you to change time periods, add new columns (like net profit, discount percent, etc.) and also easily turn these tables into charts and graphs. However, while a pivot table allows you to very easily see and visualize numbers, it only allows you to see that information along the dimension of your pivot table. So, if you are looking at the ‘location’ breakdown you can see the changes along that dimension. Same for the ‘product class’ breakdown.
But what if the interesting information that you need is at the intersection of two different dimensions? For example, both the “Midwest” and “Shirts” could individually have the numbers shown above, while sales of “Shirts in the Midwest” are down significantly. You would not be able to see this by looking at either of these pivot tables.
A quick-witted data analyst at this point will point to a flaw in my complaint- if the interesting movements in my example data are located at the intersection of the ‘location’ and ‘product class’ data, then a user could select both of those dimensions to create a new, more detailed pivot table. Something that looks like this:
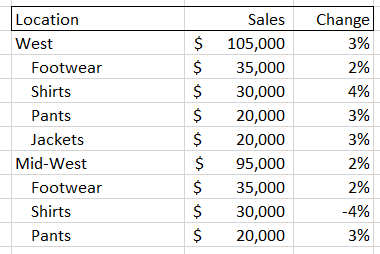
But there are two problems with this solution. First, you have to proactively find the right set of intersections. As we will soon see, the number of possible combinations for most data sets is gigantic, so it may be difficult to find the key information if you don’t have significant time and/or expertise. Second, as you increase the amount of information in your pivot tables it becomes harder to actually digest it. In the examples above, we went from a very easy-to-read set of four items plus a total value, to a much harder to digest set of 16 sub-items, 4 items, and a total value. This could easily get out of control if we added a third dimension, and that’s before adding more metrics or KPIs as columns and/or having larger numbers of sub-components for each dimension.
It's More than Just Subjects
Hopefully you have a sense of how difficult it can be for pivot tables to deal with all the different ways that subjects and groups can be broken down. Unfortunately, that is only one small problem in the world of data analysis. There are five big dimensions to data analysis. Critically, each of these components is independent of each other, meaning that pivot tables, which start to get unwieldy when handling three dimensions of interaction, are utterly hopeless in helping users to understand interesting aspects of their data that might involve seven or more dimensions of interaction. The five main classes of dimensions (which each can contain many sub-dimensions) are:
Subject Groupings
The retail grouping example I used above is really an aspect of two different dimensions of analysis – parent grouping and children grouping. When examining data from a parent group perspective we look to see how it compares to other subjects in the same group (e.g. Midwest vs. East) or compare data to the average among all siblings (e.g. Midwest vs. All Locations). When looking at children groupings, we are looking to see which sub-components are driving the overall figures. As noted in our pivot table example above, this might involve diving into multiple dimensions (e.g. 'location' + 'product class') to determine the most relevant subject.
Timing
There are different ways to create data points using time periods (sales for the day, week, month, etc.). There are also different ways to contextualize data over time periods: we might look at how a metric has changed over time, whether it has trended up or down over a certain time period, or how it compares MTD to a similar period in the past. Both the way we create data and the way we compare it are independent dimensions (e.g. you can look at how data from this month [data creation period] compares to data from the same month last year [data comparison period]).
Metrics
These are the actual figures you care about in your data, such as ‘total dollar sales’, ‘units’, ‘average price’, etc. There is some conceptual similarity between dealing with a group of metrics and dealing with a group of subjects. The key difference is that groups of subjects combine to form their parent (such as the sales for all ‘locations’ adding up to the total sales) whereas metrics are different aspects of the same subject. Pivot tables do a reasonably good job of handling this dimension, as you can typically express different metrics using columns instead of rows. Adding more than a few columns, however, can quickly overwhelm the end user, which is a problem because end users often have a large number of metrics that they potentially care about. The use of metrics is also complicated by the fact that many metrics have different aspects that function like new dimensions of analysis. For instance, you might have a total sales figure, but then there is also the change of that figure over time.
Events
These are the different types of ‘stories’ contained within your data that end users are concerned with. Stories like ‘X metric is trending up’ or ‘Y metric is now above 0 for the first time since Z date.’ Most end users have a list of hundreds of events they care about. Pivot tables typically do not even make an attempt to handle this aspect of analysis, leaving it up to the user to deduce these events from looking at the numbers.
Importance
This dimension tries to break down data by what is actually the most valuable to the end user, which requires it to sit at the intersection of all the above dimensions. It needs to weigh the inherent interest level of a particular subject, each metric of that subject, each possible time period to analyze that metric over, and each event that metric could be involved in. On top of that, this dimension incorporates other elements, such as the volume of a given subject (compared to its sibling metrics) and whether a particular event is relevant given previous reporting.
Just how crazy difficult it is to navigate each of these dimensions while running data analysis is obscured by the brilliant human brain. Humans have the ability to map layers of meaning on top of each other and simultaneously calculate across multiple dimensions of analysis. We can then synthesize the most important information found at the intersection of all the dimensions listed above- either creating a narrative, giving a presentation, or creating a set of key charts and tables. Unfortunately, this process for human beings requires expertise and intuition as they wander down pathways in the data to find those nuggets of information. It also takes a great deal of time, costs a lot of money, and can never be as thorough as a computer. Pivot tables are really just a partial shortcut- allowing data analysts to skip a couple of dimensions of analysis but still requiring them to brute-force the rest.
Time to Pivot from Pivot Tables

What if a computer could handle this task? You would then get the best of both worlds. Like a human being, it could flexibly run through multiple, independent dimensions of analysis and then synthesize its findings in a way that was easy to understand. Being a computer, it could also analyze information much more thoroughly, run its analysis very quickly, and be able to produce reports at incredible scale. infoSentience has actually created technology that can accomplish this. In brief, the key technology breakthrough is to (1) use conceptual automata designed to run an analysis for a particular dimension, (2) allow each automata to run independently, and (3) give them the intelligence to interact with the other conceptual automata so that they can come together to form a narrative. Keep following this space for more information on just how far reaching this breakthrough will be.

infoSentience's automated content today is the worst you will ever see it. That will be true if you are reading this article on the day I published it, and will also be true if you are reading it a year later. Why is that? Simple- every day, our content is doing one of two things: (1) staying the same, or (2) getting better. The ‘staying the same’ part is pretty straightforward, as our software will never get tired, make mistakes, need retraining, decide to change jobs, etc. On the other hand, we are constantly making improvements, and each of those improvements establishes a new ‘floor’ that will only get better. I call this the ‘improvement ratchet’ since it only moves in one direction- up! There are three key ways that automated content gets better over time:
- Improving Writing Quality
- Expanding the Content
- Better Audience Targeting
Improving Writing Quality
The most straightforward way that our automated content improves is by teaching our software how to write better for any particular use case. One way we learn is through feedback from our clients, as they see the written results and suggest changes or additional storylines. Another set of improvements comes from the iterative dance between the system output and our narrative engineers. When you give software the freedom and intelligence to mix content in new ways you sometimes come across a combination of information that you didn’t fully anticipate. For example, let’s look at this paragraph:
Syracuse has dominated St. Johns (winning 13 out of the last 17 contests) but we’ll soon see if history repeats itself. Syracuse and St. Johns will face off at Key Arena this Sunday at 7:00pm EST. St. Johns has had the upper hand against Syracuse recently, having won their last three games against the Orange.
This paragraph works reasonably well, but the specific combination of the first and third stories aren’t tied together as well as they could be. In this case, the final sentence (about St. Johns dominating recently) would be improved by incorporating the information from the first sentence (about Syracuse having a big advantage overall). The updated version of the last sentence would read like this:
Despite Syracuse’s dominance overall, St. Johns has had the upper hand recently, having won their last three games against the Orange.
This improvement is an example of what we call an ‘Easter Egg’, where we add written intelligence that is targeted to an idiosyncratic combination of events. Our reports contain hundreds of possible events adding up to millions of possibilities. Adding intelligence to these events allows them to combine together properly and avoid repetition. However, there’s no way to build out specific language for all possible interesting combinations in advance. As we read actual examples we come across unique, interesting combinations. We can then add specific writer intelligence that covers these combinations to really make the reporting ‘pop’.
Critically, this intelligence is usually a bit broader than just a simple phrase that appears in only one exact combination of events. In the example above, for instance, we would add intelligence that looks for the contrast between a team’s overall record against an opponent and their recent record and allow that intelligence to work in any such situation. We also need to make good use of our repetition system to make sure that all these Easter Eggs don’t start tripping over themselves by repeating information that was already referenced in the article.

Expanding the Content
Another way that content improves is by quickly expanding into similar use cases. For example, when we started with CBS we only provided weekly recaps for their fantasy baseball and football players. We soon expanded to offering more fantasy content: weekly previews, draft reports, year-end recaps, and more. Because those were successful, they then asked us to provide previews and recaps of real-life football and basketball games. We quickly added soccer, and then expanded the range of content by also providing gambling-focused articles for each of those games.
This same story has played out with many of our other clients. One of the big reasons for this is because automated content is so new that it’s often difficult to grasp just how many use cases it has. After seeing it in action, it’s much easier to imagine how it can help with new reporting tasks.
The other big reason that automated content often quickly expands is because the subsequent use cases are often cheaper to roll out due to economies of scale. There are three main steps to generating automated content:
- Gather data
- Create the content
- Deliver it
Each of these steps is usually much easier when rolling out follow-up content. In the case of Step #1, gathering data, it is sometimes the case that literally the exact same data can be used to generate new content. This happened when we expanded from general previews to gambling-focused previews for live sports games, which just emphasized different aspects of the data we were already pulling from CBS. Even if there are additional data streams to set up, it’s usually the case that we can still make use of the original data downloads as well, which typically reduces the amount of set up that needs to take place.
When it comes to Step #2, creating the content, infoSentience’s ‘concept based’ approach pays big dividends. Instead of creating Mad-Lib style templates, infoSentience imparts actual intelligence into its system. That allows the system to be flexible in how it identifies and writes about the most important information in a data set. It also means that it can quickly pivot with regard to things like: the subjects it writes about, the time periods it covers, the length of the articles, the way it adds visualizations, the format of the report, the importance of certain metrics and storylines, and many more. Entire new pieces of content can often be created just by turning an internal ‘dial’ to a new setting.
Finally, for Step #3, there is usually a tremendous amount of overlap when it comes to the delivery process for follow-up content. Typically, we will coordinate closely with our clients to set up an initial system for delivery. This might entail dropping our content into an API ‘box’ that our clients then access, but other times we send out emails ourselves or set up a web site to host the content. We might also set up a timing system to deliver content on demand or at particular intervals. It is often the case that these exact same procedures can be used for follow-up content.
A great example of how all these steps came together is when we expanded to providing soccer content for CBS. In that case, the data pulldown and delivery procedures were identical, requiring no changes at all from CBS. While we did create some soccer-specific content, much of the sports intelligence for soccer was able to make use of the existing sports intelligence we had built into the system.

Better Audience Targeting
Finally, another way that automated content improves is from user feedback. Automated content allows for a level of A/B testing that would be impossible using any other method. I’ve already mentioned that our AI can change what it focuses on, its time periods, length, format, and more. It can also use different phrase options when talking about the same information, and even change the ‘tone’ that it uses. All of these options can be randomized (within bounds) when delivering content on a mass scale. It is a simple task to then cross-check user engagement with each of these variables to determine what the optimal settings are.
It's also possible to allow individual readers to customize their content however they want it. All of the ‘options’ mentioned above can be exposed to end users, allowing them to specify exactly what they want to see. This not only allows users themselves to improve the content they see, but also gives organizations a better understanding of the information that each of their customers really care about.
Conclusion
So much of our time in business and life is spent in a losing fight against entropy. Automated content provides a welcome break from that struggle. Set it up and enjoy great benefits from day one, knowing that the only changes that will ever take place are for the better.

Just being honest, I sometimes suffer from engineering arrogance. I’ll look at software that another company has built and think “that’s not that hard.” Well, nothing close to that thought crossed my mind after playing around with ChatGPT. As someone who has spent the last 12 years working on Natural Language Generation (NLG) technologies, I found its writing capabilities astonishing. If there was an engineering Nobel Prize, the OpenAI team should win.
That said, ChatGPT has not (thankfully) actually achieved General Artificial Intelligence yet. There are several areas where it struggles compared to a smart human being, particularly when it comes to analyzing and reporting on numeric data sets. Conveniently for me, many of the areas where ChatGPT is weak are the same areas where the technology I have been working on is strong. In this post, I’m going to run through some of the weaknesses of ChatGPT when dealing with data, and also talk about an alternative software method that successfully deals with those challenges.
Problem #1: It's a Black Box that Makes Guesses
You want your reports to be accurate, and if they’re not accurate then you want to know why. Unfortunately, the technology underlying ChatGPT doesn’t allow for either consistent accuracy or easy debugging. While this is an oversimplification, ChatGPT essentially creates digital neurons that each try to understand some component of reading and writing text. When writing, these neurons collectively come up with a probability of which words to use at any given point in creating a written document. This means that if it is analyzing your data and writing a report, it might ‘guess’ wrong when trying to interpret or describe what’s going on. Small, subtle changes to the data could be enough to make it go down the wrong pathway. Unfortunately, reports that are 98% accurate are usually not good enough.
When ChatGPT does go wrong, the sheer complexity of its underlying technology makes it very hard to figure out why it failed. There are billions of neurons (175 billion in the case of ChatGPT4) involved in making ChatGPT run, and because they are potentially all involved in deciding each word in a report, there is no way to succinctly describe the path the computer took when it went from a blank page to a completed report. Asking ChatGPT to fully describe its thought process is akin to asking you how you processed the photons coming into your eyes. The mechanism is hopelessly opaque, even to the system that is doing the processing.
Human thinking is different. We start with well-defined concepts (“up”, “week”, “revenue”) and then mix them together to form new concepts (“revenue was up for the week”). We can then manipulate these concepts using logical operations and continue to combine concepts into bigger structures (like complex thoughts or written paragraphs). Crucially, we can apply this process of conceptual thinking to our own thought process, giving us the ability to explain how we came to a conclusion.
There is a way to mimic human-style thinking in software by using conceptual automata. These are pre-defined concepts that exist within an ontology and can be combined with each other to form larger concepts. Because they are not probabilistic, they always follow the same pathways when analyzing data, making sure that their final analysis is 100% accurate. Using sophisticated debugging tools, each of these pathways can be made visible to a narrative engineer, so they can very quickly determine exactly why any given sentence, phrase, or number appeared in a narrative.
Problem #2: Struggling with Logical Operations
ChatGPT can play chess, despite having never seen a chess board. It’s actually not terrible, especially in the opening. While that certainly would make it seem like it can handle logical thinking, it’s really an illusion. ChatCPT is essentially a super-sophisticated auto-complete system. So, if you start off by asking the system for a chess move that comes after 1.e4, it might respond with 1. e5. That’s not because it understands the value of moving your pawn forward, but rather because it has read through the annotations of millions of chess games and knows that e5 often follows e4.
For as long as you play ‘book moves’ (those typically played in a chess opening) ChatGPT will keep humming along great. But once you get to the ‘middle game’, where you are now playing a unique contest, ChatGPT will start to struggle. Sometimes, it will even suggest making an illegal move, like moving your own piece on top of another of your pieces.
This is a problem when dealing with your data. While there are elements of your data that are not unique, the totality of information contained within your data sets creates a never-before-seen analysis question. Essentially, it’s one big ‘middle game’ in chess, where you can’t follow hard and fast rules anymore and instead have to rely on real logical thinking.
A Conceptual Automata System (CAS) solves this problem by incorporating logical operations directly into the foundation of the software. As I mentioned before, conceptual automata work by allowing multiple concepts to be combined into larger concepts. However, there really isn’t a bright line difference between what we might refer to as a ‘tangible’ concept, such as ‘revenue’ and a logical operation concept such as ‘last week’ or ‘double’. Therefore, when the CAS applies a logical transformation, such as changing ‘revenue’ to ‘revenue last week’, it simply creates a new concept that combines the tangible concept of revenue with the logical operation of moving the time period back one week.
Human beings are proof that the potential ways of combining tangible and logical concepts together are near infinite, as we can offer an analysis of almost any situation. While a CAS is not currently as flexible in its domain knowledge as ChatGPT, within an area that it has expertise it can mix together concepts with human-like fluidity. Because it understands all of the sub-components involved in creating larger scale concepts, it maintains a fundamental understanding of its results, giving it the ability to then write about it intelligently.

Problem #3: Not Adapting to New Information
ChatGPT has gobbled up fantastic amounts of written material. In fact, ChatGPT has essentially ingested every piece of written material available on the internet, meaning every blog post, article, and Tweet, along with every book ever written. It needs that massive amount of scale precisely because it doesn’t think conceptually like human beings do. When we learn a new thing, we typically try to fit it into already existing concepts and then understand how the new thing is different. For example, if you had never heard of soccer but knew all about hockey, you would pretty quickly be able to understand the dynamics of the game by mapping the new soccer concepts on top of the ones you had for hockey. ChatGPT, on the other hand, derives something akin to a concept by looking at the interactions of massive amounts of information. These ‘quasi concepts’ can’t really be manipulated or merged with new information entering the system, as they can only be built by looking at an entire training set at one time.
It takes a long time to go through the entire history of written content, so ChatGPT is trained over a set time period (usually several months) and then its model is fixed from that point forward. It might seem like it is adapting or learning when you chat with it, but in fact it is merely responding to you by applying some already existing aspect of its model to what you are saying. It cannot create new concepts until the entire model is retrained.
This is a problem, because one thing that it hasn’t ingested (hopefully) is your internal reporting, or the internal reporting of any of your competitors. This means ChatGPT would be approaching your data, and your reporting needs and preferences, from anew. It could try to apply already existing concepts it had derived to your data, but it wouldn’t be able to create any new conceptual information. It would therefore struggle to incorporate feedback from you as to what to look for in the data, how to weight the significance of different events, how to use jargon or unique metric names, and many other aspects to reporting on your data that require new knowledge.
Not There Yet
ChatGPT is taking the world by storm, and for good reason. Its ability to understand written text and communicate on a human level is truly astounding, and marks a significant change in the history of human technology. That said, when it comes to writing reports based on data, it currently has the potential to make significant errors, is difficult to debug, struggles with logical operations, and has a hard time incorporating new information after it has been trained. Any of these by themselves would hamper ChatGPT’s ability to reliably analyze data and report on it. Taken collectively, they completely prevent ChatGPT from playing a significant role in automating data-based reporting in the near term.
In contrast, CAS can deliver 100% accuracy, is easy to debug, can handle all basic logical operations (changing time spans, creating sets, arithmetic, etc.), and can be fairly quickly trained to report on data of any kind. For now at least, this makes it the ideal solution for automated reporting. Given that CAS is strong where ChatGPT is weak and vice versa, could merging the two technologies provide an even more powerful solution, and perhaps even get us closer to General AI? My answer to the question is probably (!), so keep a look out for future blog posts on that topic.

I’ve written in this blog before about the importance of avoiding cookie-cutter narratives when reporting on data. The two main issues being that: (1) templates are not flexible enough to report on the unique outcomes involved in any data set, and (2) people reading the reports will start to tune them out when they see the same pieces of information in the same arrangement.
The need to have flexible and original narratives applies just as well to how you visualize data. Unfortunately, most data dashboards, such as Tableau or Power BI, are built to have a set of default visualizations relating to the data. For example, a sales report might default to showing gross sales over the past year. But what if ‘gross sales over the past year’ isn’t the big story? For instance, what if the big story was a steep rise in returns over the past three months?
The ideal solution is straightforward- ditch the ‘canned’ visuals and have software automatically highlight the visual information that is most important to the end user. These visuals can be paired with an automated narrative that also automatically surfaces the most important information. Ideally, both the narrative and visual elements of the report will be aligned- quickly allowing the reader to both read and see the things they need to know.
Using Conceptual Automata
This capability is possible if you use automated reporting software that uses conceptual automata. What the heck are conceptual automata? A full breakdown would require a long answer, but at a very high level, conceptual automata break every story or event within a dataset into a set of components. So, for a stock story such as ‘stock on a 5-day streak of beating the market’, the system understands this as the mix of its constituent parts: [streak] [of stock] [beating market] [for five days].
Because the Conceptual Automata System (“CAS”) understands how each sub-component combines to make up the full story, intelligence for how to visualize the story can be placed on the sub-components. This allows the CAS to ‘share’ the intelligence from one story with other stories that have the same sub-components, and also allows the system to visualize any combination of narrative information.

This is similar to how human beings think. After all, if you knew how to visualize a story like ‘stock on a 5-day streak of beating the market’, you would have no problem visualizing the story ‘stock on a 5-day streak of underperforming the market’, or a story like ‘healthcare stock on a 5-day streak of beating the average healthcare stock.’
Human-level flexibility allows a CAS to create charts that cover different time periods and can include multiple subjects. It can understand all the different ways a story could be visualized (line/pie/bar chart, table, etc.) and the benefits and drawbacks of each form factor. Some of those form factors might use more visual space, and the CAS has the capability to understand how to best make use of the available visual space to convey the most information. It might choose to have one large, very visually compelling chart, or two smaller charts, depending on the underlying importance of the information.
Telling the Visual Story
Because the CAS understands the conceptual underpinnings of each visualizer, it can go beyond just showing you the numbers like you’d see in a standard issue dashboard chart. Those charts might show you all the information, but they won’t necessarily make it easy to see why that data is compelling. This is where chart ‘Scribbles’ come into play. ‘Scribbles’ is a catch-all term for human touches that a CAS system can add to a chart to make it easy for the viewer to quickly understand its importance. For example, when a chart is visualizing a metric having moved up in X out of the last Y periods, the chart could highlight the positive movement in green, while showing the negative movement in red. In other situations it might use arrows to point out key data points, or add a trend line to compare movement to.
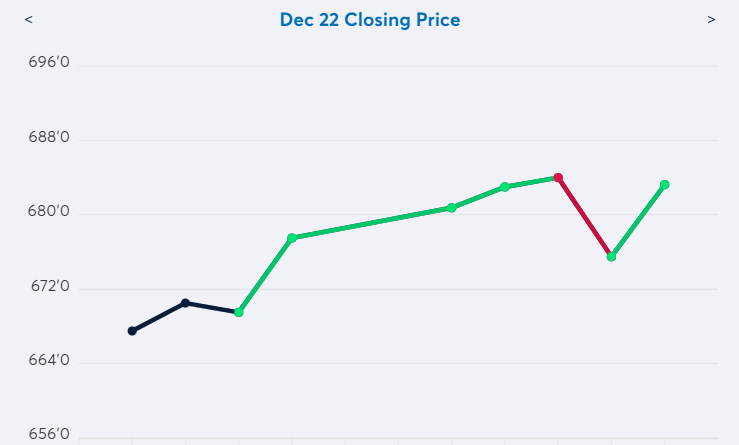
These additions are not necessary of course, but they help make it that much easier for decisionmakers to easily understand what they need to know. When reporting on data, good writing is all about allowing the reader to spend less effort understanding the report so that the reader can spend more effort thinking about the implications of the report. By holding the viewer's hand as they look at a chart, Scribbles allow a little section of the viewer's brain to relax, freeing up that brainpower to be used for something more valuable.
User Control
The CAS can default to showing the most compelling visuals, but why stop there? After all, the reader is the ultimate judge of what is important, so why not give them the ability to visualize any piece of information within a narrative? That’s exactly what a CAS interactive dashboard is able to do. The CAS can visualize any event within the data, so that allows end users, with the press of a button, to turn any sentence in a narrative into a chart or graph. This not only allows users to quickly visualize information but can also allow them to create charts and graphs to share as a part of a presentation. Alternatively, they can turn a sentence into a table if they want to view the data that the sentence was built from. That allows them to quickly dig into underlying data to understand what sub-components might need more examination.
The Whole Package
Taken collectively, concept-based visuals create a step change in how reports integrate visual information. Instead of pre-set charts and graphs, users see the charts and graphs that highlight the most important information they need to know. Those visualizations are then formatted in such a way that the user can quickly understand the significance of each visual element, whether that might mean highlighting sections of a chart or adding arrows and text. Finally, the user is given the freedom to turn any part of a report into a visual element, whether that be a chart, graph, or table.
The user can even turn any aspect of a report into an automated video…but that will have to be the subject of a blog post sometime in the future 😊

In the olden days, if you wanted to send out a report to your employees, or an update to your clients, or a letter intended for prospective customers, you only had two options:
Option #1: Mass Communication
You create one piece of content and send this off to everybody. If it was a report, then everybody got the same report. If it was a letter to your clients, then every client got the same letter. This has the benefit of being cheap and fast, allowing you to reach as many people as possible. The drawback is that everybody gets the same content regardless of their particular circumstances.
Option #2: Custom Communications
Every client, potential customer, or employee gets content that is specifically written for them. This has the advantage of making the communication maximally effective for each end user. The cost of course, being that it takes time and money to create each communication. In many cases, it’s not feasible to send out a given number of narratives even with an outsized budget.
But what if you didn’t have to choose the least bad option? That is what’s possible with Mass Custom Communication (MCC), which takes the best parts of each option, allowing you to deliver insightful, impactful reports on a near infinite scale. But before we talk more about what MCC is, let’s talk about what it isn’t. MCC is not a form letter and it is not a ‘Mad Libs’ style narrative. We’ve all been the recipient of communications like that, and they barely register as being customized at all, let alone making us feel like they have been written just for us. This goes double if the narrative or report is part of an ongoing series of communications which all use the same template.
In order to create true MCC, you need two things: (1) a rich data set, and (2) Natural Language Generation (NLG) software that can truly synthesize that data set and turn it into a high-quality narrative. Let’s take these in order. First, you need a rich data set because you must have enough unique pieces of data, or combinations within that data, to write up something different for each end user. In essence, you need ‘too much’ information to fit into a template.
Once you have ‘too much’ information, you need high-quality synthesis from an AI NLG system. This system can go through thousands of data points to find the most relevant information for each end user. It then can automatically organize this information into a narrative with clear main points and interesting context, so that the end user is able to read something that feels unique and compelling to them. For example, a salesperson can get a weekly report that not only tells them about the top-line numbers for their sales this week, but also contextualizes those numbers with trends from their sales history and larger trends within the company.

Individual Outreach
A great example of the power of MCC comes from the world of fantasy sports. For those of you unfamiliar with how fantasy sports work, you and your friends each draft players within a given sport, and then your ‘team’ competes with other teams in the league. It’s sort of like picking a portfolio of stocks and seeing who can do the best.
People love playing fantasy sports, but because each team is unique, and because there are millions of fantasy players, people were never able to get stories about their fantasy league the same way that they get stories about the professional leagues. With the advent of MCC, suddenly they could, and CBS Sports decided to take advantage of it.
For the last 10 years, we’ve written up stories about what happened for every CBS fantasy team every week, creating game recaps, game previews, draft reports, power rankings, and many other content pieces, each with headlines, pictures, and other visual elements. This was actually infoSentience’s first product, so it is near and dear to my heart. We’ve now created over 200 million unique articles which give CBS players what we call a ‘front page’ experience, which covers their league using the same types of content (narratives, headlines, pictures) as the front page of a newspaper. Previously, they could only get a ‘back page’ experience that showed them columns of stats (yes, I realize I’m dating myself with this reference).
Critically, quality is key when it comes to making these stories work. Cookie-cutter templates are going to get real stale, real fast when readers see the same things over and over again each week. Personalization involves more than just filling in names and saying who won, it’s about finding the unique combinations of data and events that speaks to what made the game interesting. It’s writing about how you made a great move coaching AND how that made the difference in your game AND how that means you are now the top-rated coach in your league.
This type of insight is what makes for compelling reading. Open rates for the CBS weekly recap emails we send out are the highest of any emails CBS sends to their users. If you are sending out weekly reports to each of your department managers, or monthly updates for each of your clients, they have to be interesting or they’re not going to be read. If each report is surfacing the most critical information in a fresh, non-repetitive manner, then end users will feel compelled to read them.
Long Tail Reporting
Reports don’t necessarily have to be targeted at individuals in order to achieve scale. You might also just need to write a lot of reports using many subsets of your data. These reports might be targeted towards groups, or just posted onto a website for anybody to read. This might be better labeled Mass ‘Niche’ Communications, but it definitely falls under the MCC umbrella.
CBS has not only taken advantage of MCC for their fantasy product, but has also applied it to live sports. They leverage our automated reporting technology to supplement their newsroom by writing stories they otherwise wouldn’t have time for. Being one of the major sports sites in the US, they obviously have plenty of quality journalists. That still doesn’t mean that they are capable of covering every single NFL, NBA, college basketball, college football, and European soccer match, let alone writing up multiple articles for each game, covering different angles such as recapping the action, previewing the game, and covering the gambling lines.
That’s where our technology comes in. We provide a near limitless amount of sports coverage for CBS Sports at high quality. That last part is once again key. CBS Sports is not some fly-by-night website looking to capitalize on SEO terms by throwing up ‘Mad-Libs’ style, cookie-cutter articles. These write-ups need to have all the variety, insight, and depth that a human-written article would have, and that’s what we’ve delivered. For example, take a look at this college football game preview. If you just stumbled across that article you would have no idea it was written by a computer, and that’s the point.
Our work for IU Health is another example of this type of reporting. We automatically write and update bios for every doctor in their network, using information such as their education history, specializations, locations, languages, and many other attributes. We even synthesize and highlight positive patient reviews. Like with CBS, these bios would be too difficult to write up manually. There are thousands of doctors within IU’s network, and dozens come and go every month. By automating the bios, IU not only saved themselves a great deal of writing, but also made sure that all their bios are up to date with the latest information, such as accurate locations and patient ratings.
Your Turn?
If you are in a situation where you are either (A) not creating all the content you need because you don’t have the workforce, or (B) using generic reports/communications when you would really benefit from having a custom message, then hopefully this article opened your eyes to a new possibility. Mass Custom Communication allows you to have your cake and eat it too. Maybe your use case can be the one I talk about in the next version of this article.

[Note: All of the following concerns AI’s ability to write about specific data sets, something very different from ChatGPT-style natural language generators]
We all know the basics for why good writing is important in business. Decision makers want to read reports that are accurate, impactful, and easy to understand. With those qualities in mind, let’s take a look at this short paragraph:
Widgets were down this month, falling 2.5%. They were up the last week of the month, rising 4.5%.
Assuming the numbers are correct, the sentences would certainly qualify as being ‘accurate’. The metrics mentioned also seem like they would be ‘impactful’ to a widget maker. Is it ‘easy to understand’? Here’s where it gets a bit trickier. Both sentences by themselves read fine, but when you put them together, there’s something missing. The writing comes across as robotic. Ideally, we’d want the sentences to read more like this:
Widgets were down this month, falling 2.5%. The last week of the month was a bright spot though, as sales rose 4.5%.
This is conveying the exact same basic information as before: (1) monthly sales down, and (2) last week up. But the sentence contains a critical new word: though. Transition words like ‘though’, ‘however’, ‘but’, and so on play a critical role in helping our brains not just download data, but rather tell the story of what is happening in the data. In this case, the story is about how there’s a positive sign in the time series data, which is also emphasized by using the ‘bright spot’ language.
If a manager was just reading the first example paragraph, it’s likely that they would be able to fill in the missing info. After reading the second sentence their brain would take a second and say “oh, that’s a good sign going forward in the midst of overall negative news.” But having to make the reader write the story in their head is not cost free.
After all, it's not enough to just understand a report. Whether it’s an employee, C-suite executive, client, or anybody else, the point of a report is to give someone the information they need to make decisions. Those decisions are going to require plenty of thinking on their own, and ideally that is what you are spending your brainpower on when reading a report.
This brings me to my alternate definition of what ‘good writing’ really means: it’s when you are able to devote your brainpower to the implications of the report rather than spending it on understanding the report.
So what are the things that we need to allow our brain to relax when it comes to understanding data analysis? There are three main factors, which I call “The Three T’s”, and they are:
- Trust – you have to trust that the numbers are accurate of course, but real trust goes beyond that. It’s not just feeling confident about the stories that are on the page, but also feeling confident that there isn’t anything critical that is being left out.
- Themes – the report can’t just be a series of paragraphs, there has to be a ‘through-line’ that connects everything, allowing you to quickly grasp which stories are central and which ones are secondary.
- Transitions – this can be seen as a mini version of the ‘Themes’ factor. Transitions and other emotional language, as shown in our example above, can help keep your thoughts on track as you make your way through each sentence.
All of these things are hard enough for a human data analyst or writer to pull off (am I extra nervous about my writing quality for this post? Yes, yes I am). For most Natural Language Generation (NLG) AI systems, nailing all Three T’s is downright impossible. Each factor presents its own unique challenges, so let’s see why they are so tough.

Trusting AI
The bare minimum for establishing trust is to be accurate, and that’s one thing that computers can do very easily. Better, in fact, than human analysts. The other key to establishing trust is making sure every bit of critical information will make it into the report, and this is where AI’s have traditionally struggled. This is because most NLGs in the past used some sort of template to create their narratives. This template might have a bit of flexibility to it, so a paragraph might look like [1 – sales up/down for month] [2 – compare to last year (better or worse?)] [3 – estimated sales for next month]. Still, templates like that aren’t nearly flexible enough to tell the full story. Sometimes the key piece of information is going to be that there was a certain sub-component (like a department or region) that was driving the decrease. Other times the key context is going to be about how the movement in the subject of the report was mirrored by larger outsize groups (like the market or economic factors). Or, the key context could be about the significance of the movement of a key metric, such as whether it has now trended down for several months, or that it moved up more this month than it has in three years.
There’s no way to create a magic template that will somehow always include the most pertinent information. The way to overcome this problem is to allow the AI system to work the same way a good human analyst does- by first analyzing every possible event within the data and then writing up a report that includes all of those events. But having this big list of disjointed events makes it that much more difficult to execute on the second ‘T’: Themes.
Organizing the Story
How does the AI go from a list of interesting events to a report that has a true narrative through line, with main points followed by interesting context? The only way to do this is by embedding conceptual understanding into the AI NLG system. The system has to be able to understand how multiple stories can come together to create a theme. It has to be able to understand which stories make sense as a main point and which stories are only interesting as context to those main points. It also needs to be able to have the ability to fit those stories into a narrative of a given length, thereby requiring some stories to be told at a high level rather than going into all of the details.
Writing the Story
Just like how the importance of transitions are a small-scale version of themes, the challenges for dealing with transitions are a small-scale version of themes. That doesn’t make them any easier, unfortunately. The issue with themes is structural- how do I organize all the key pieces of information? The problem with transitions comes about after everything has been organized and the AI has to figure out how to write everything up.
Again, the solution is to have an AI system that understands conceptually what it is writing about. If it understands that one sentence is ‘good’ and the next sentence is ‘bad’, then it is on the path to being able to include the transitions needed to make for good writing. Of course, it’s not quite that simple, as there are many conceptual interactions taking place within every sentence. For example, starting out a sentence with “However, …” would read as robotic if happening twice within the span of a few sentences. Therefore, the AI system needs to find a way to take into account all of the conceptual interactions affecting a given sentence and still write it up properly.

Have no Fear!
These are all complex challenges, but thankfully infoSentience has built techniques that can handle The Three T’s with no problems. Whether it’s a sales report, stock report, sports report, or more, infoSentience can write it up at the same quality level as the best human writers. Of course, we can also do it within seconds and at near infinite scale (Bill Murray voice- “so we got that going for us”).